3 Tier 아키텍처
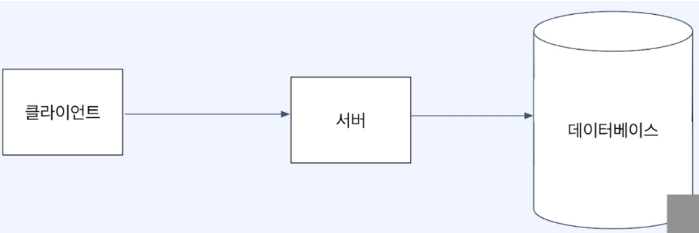
클라이언트는 서버에 데이터를 요청 → 서버는 데이터베이스에게 데이터를 요청
데이터베이스

데이터베이스는 파일을 관리하는 서버
클라이언트는 json을 통해서 서버에게 데이터를 요청 → 서버는 SQL을 통해서 MySQL 서버에 데이터를 요청 (MySQL 입장에서 본다면 서버는 클라이언트와 같은 역할)
MySQL 서버

MySQL 내부에서는 MySQL 엔진 → 스토리지 엔진 → 운영체제 → 디스크를 거쳐 데이터를 탐색하고 그 결과를 돌려줌
- MySQL 엔진 : 판단과 명령을 하는 두뇌
- 스토리지 엔진 : 판단을 수행하는 역할
MySQL 엔진

MySQL 엔진은 쿼리 파서, 전처리기, 옵티마이저, 쿼리 실행기로 이루어져 있음
- 쿼리 파서 : SQL을 파싱하여 Syntax Tree를 만듦 → 이 과정에서 문법 오류 검사가 이루어짐
- 전처리기 : 쿼리 파서에서 만든 Tree를 바탕으로 전처리 시작 → 테이블이나 칼럼 존재 여부, 접근 권한 등 Semantic 오류 검사
- 쿼리 파서와 전처리기는 컴파일 과정과 매우 유사하지만, SQL은 프로그래밍 언어처럼 컴파일 타임때 검증 할 수 없어 매번 구문 평가를 진행해야 함
쿼리 파서 예시

옵티마이저
- 쿼리를 처리하기 위한 여러 방법들을 만들고, 각 방법들의 비용 정보와 테이블의 통계 정보를 이용해 비용을 산정
- 테이블 순서, 불필요한 조건 제거, 통계 정보를 바탕으로 전략을 결정 (실행 계획 수립) → 옵티마이저가 생각하기에 가장 최적이라고 생각되는 방법을 선택하는 역할을 가지고 있음
- 옵티마이저가 어떤 전략을 결정하느냐에 따라 성능이 많이 달라진다.
- 가끔씩 성능이 나쁜 판단을 해 개발자가 힌트를 사용해 도움을 줄 수 있다. → explain이라는 명령을 통해 옵티마이저가 어떤 방법을 결정했는지 확인할 수 있는 쿼리가 있음
쿼리 실행기

- 쿼리 실행기는 옵티마이저가 결정한 계획대로 스토리지 엔진에 요청을 하는 역할 → 이때 Handler API 사용
- 스토리지에 요청을 하는 것 → Handler 요청
- Handler API를 만족하는 스토리지 엔진만 구현할 수 있다면 어떤 식이든 직접 구현하여 스토리지 엔진을 추가하여 사용할 수 있음
쿼리 캐시가 주는 인사이트

- MySQL 5.0까지는 쿼리 캐시라는 것이 있었음
- 8.0 대에 들어와서 쿼리 캐시는 폐기됨
- 쿼리 캐시는 데이터를 직접 캐싱하는 것이기 때문에 만약 테이블의 데이터가 변경이 되면 캐시도 같이 변경되어야 함
- 이 과정에서 생기는 문제가 쿼리 캐시가 주는 이점보다 더 컸기 때문에 폐기가 됨
cf) Oracle
- 소프트 파싱 : SQL, 실행 계획을 캐시에서 찾아 옵티마이저 과정을 생략하고 실행 단계로 넘어감
- 하드 파싱 : SQL, 실행 계획을 캐시에서 찾지 못해 옵티마이저 과정을 거치고 나서 실행 단계로 넘어감
정리
- MySQL에는 소프트 파싱이 없음
- 하지만 5 버전까지는 쿼리 캐시가 있었음
- 쿼리 캐시는 SQL에 해당하는 데이터를 저장하는 것
- 쿼리 캐시는 데이터를 캐시하기 때문에 테이블의 데이터가 변경되면 캐시의 데이터도 함께 갱신시켜줘야 함
- Oracle에는 소프트 파싱이 존재
- 실행 계획까지만 캐싱
- 하지만 모든 SQL과 맵핑해 데이터까지 캐싱하지는 않음 (힌트나 설정으로 가능하긴 함)
- MySQL의 쿼시 캐리, Oracle의 소프트 파싱 모두 성능 최적화를 위해 캐시라는 기술을 도입한 사례
- 그러나 캐시의 범위가 다르다.
- 캐시를 도입할 때는 항상 만료 정책을 고려해야 함
- 쿼리 캐시는 소프트 파싱에 비해 조회 성능이 더 높지만, 캐시 데이터 관리에 더 높은 비용이 들어감
- 모든 기술은 트레이드 오프이다. → 이 경우는 캐시의 범위를 어떻게 잡느냐에 따라 조회와 성능 사이의 문제이다.
스토리지 엔진
- 디스크에서 데이터를 가져오거나 저장하는 역할
- MySQL 스토리지 엔진은 플러그인 형태로 Handler API 만 맞춘다면 직접 구현해서 사용할 수 있다.
- InnoDB, MyIsam 등 여러개의 스토리지 엔진이 존재
- 8.0대 부터는 InnoDB 엔진을 디폴트
InnoDB
- 핵심 키워드 : Clustered Index, Redo - Undo, Buffer pool
2023 KAKAO Tech Campus_BackEnd 필수 과정
DB(MySQL) 강의 정리 내용입니다.
'🔍 CS > 데이터베이스' 카테고리의 다른 글
| SNS 모델링으로 배우는 정규화 / 비정규화 - 07. 실무에서의 정규화 비정규화에 대한 고민들 (0) | 2023.06.04 |
|---|---|
| SNS 모델링으로 배우는 정규화 / 비정규화 - 01. 정규화 - 비정규화 핵심 이론 (0) | 2023.06.04 |
| MySQL 소개 - 01. MySQL을 학습하는 이유 (0) | 2023.06.04 |
| 대용량 시스템에 대한 이해 - 03. 대용량 시스템 아키텍처 맛보기 (0) | 2023.06.04 |
| 대용량 시스템에 대한 이해 - 02. 왜 데이터베이스가 병목일까? (0) | 2023.06.04 |

