
SQL문이 들어오게 되면, 바로 테이블에 접근하는 방식보다는

중간에 인덱스라는 테이블을 거쳐서 접근을 한 번 필터링 하고 테이블로 접근을 하는 것이 훨씬 빠름
→ 검색 조건이 인덱스에 부합하다면, 테이블에 바로 접근 하는 것보다 인덱스를 통해 접근하는 것이 매우 빠르다.
그렇다면 테이블에 접근하지 않고, 인덱스로만 데이터 응답을 내려줄 순 없을까? → 커버링 인덱스
커버링 인덱스

예시 query
SELECT 나이
FROM 회원
WHERE 나이 < 30
→ 필요한 데이터는 나이 1개이다. (이는 인덱스 테이블에 있음)
→ 이러한 경우는 테이블에 접근하지 않고 인덱스 테이블의 접근으로 응답이 끝남 (빠르다)
다른 예시 query
SELECT 나이, id
FROM 회원
WHERE 나이 < 30
→ id 필드도 MySQL에서는 PK 값이 클러스터링 인덱스이기 때문에 모든 index 테이블에 다 존재 (id 값이 추가가 되어도 여전히 커버링 인덱스처럼 동작을 함)
따라서 MySQL에서는 PK가 클러스터 인덱스이기때문에 커버링 인덱스에 유리
→ 커버링 인덱스 : 테이블에 접근하지 않고 인덱스로만으로도 데이터 응답을 충분히 줄 수 있는 query라면 인덱스로만 커버하겠다는 의미
커버링 인덱스로 페이지네이션 최적화를 어떻게 할 수 있을까?
예시) 나이가 30이하인 회원의 이름을 2개만 조회(limit = 2를 걸어준다)
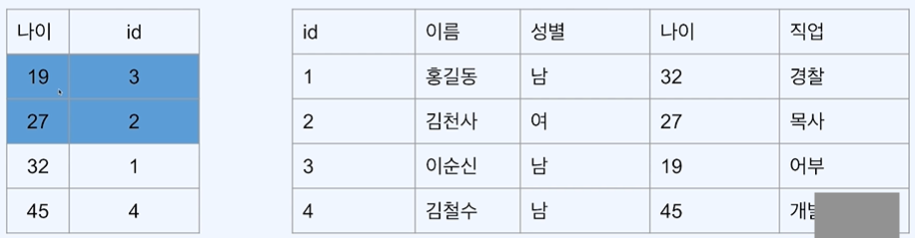
나이가 30인 id를 2개를 찾음 → 원본 데이터 찾기
문제)
지금은 2개밖에 안 나왔지만, 만약 1000개의 데이터가 발견이 되었다면, 1000개에 대한 데이터 접근이 모두 일어난다.
데이터베이스의 성능과 관련해서는 디스크의 랜덤한 I/O를 줄여야 함
→ 커버링 인덱스가 아닌 그냥 인덱스만 타고 원본 데이터만 찾아가게 된다면 그만큼 랜덤한 I/O가 발생
커버링 인덱스 적용
with 커버링 as (
SELECT id
FROM 회원
WHERE 나이 < 30
LIMIT 2
)
SELECT 이름
FROM 회원 INNER JOIN 커버링 on 회원.id = 커버링.id
id 값만 먼저 2개를 찾아오기 때문에 (나이와 id가 인덱스로 커버 가능) → 원본 데이터에 대한 테이블 접근이 없음 (불필요한 랜덤 접근을 줄일 수 있음)
정리
order by, offset, limit 절로 인한 불필요한 데이터블록 접근을 커버링 인덱스를 통해 최소화
2023 KAKAO Tech Campus_BackEnd 필수 과정
DB(MySQL) 강의 정리 내용입니다.
'🔍 CS > 데이터베이스' 카테고리의 다른 글
| 타임라인 최적화 - 03. 서비스가 커질수록 느려지는 타임라인 (0) | 2023.06.06 |
|---|---|
| 타임라인 최적화 - 01. 타임라인이란? (0) | 2023.06.06 |
| 페이지네이션 최적화 - 03. 오프셋 기반 페이징 구현의 문제(1) (0) | 2023.06.06 |
| 페이지네이션 최적화 - 01. 페이지네이션이란 (0) | 2023.06.06 |
| 조회 최적화를 위한 인덱스 이해하기 - 08. 인덱스를 다룰 때 주의해야 할 점 (0) | 2023.06.04 |


